What is Look-alike Modeling and How Does it Work?
Look-alike modeling is a core technique in audience targeting — one that lets advertisers find new potential customers who share the characteristics and behaviours of their best existing ones. This guide explains what look-alike modeling is, how it works step by step, and what it can practically be used for in digital advertising and marketing.
What is Look-alike Modeling?
At its simplest, look-alike modeling is the process of identifying groups of people (audiences) who look and act like a business's most profitable customers. Consider an e-commerce retailer that has determined its highest-value shoppers spend over $100 per order, purchase cosmetics and perfumes, and buy at least twice a month. Look-alike modeling makes it possible to find more people who fit that profile across the wider internet — people who may never have visited that retailer's site but who behave in the same way as customers already known to convert well.
How Does Look-alike Modeling Work?
Like most techniques in digital advertising, look-alike modeling relies on data and algorithms. It is most commonly conducted inside a data-management platform (DMP), which provides the data infrastructure and tooling needed to run the process end to end. Some demand-side platforms (DSPs) also offer built-in look-alike modeling functionality.
The process breaks down into three steps.
Step 1: Collect Data
Look-alike modeling requires data — and plenty of it. For results to be accurate, a combination of first-party, second-party, and third-party data needs to be gathered from both online and offline sources.
Where that data comes from depends on the type of organization running the model. A survey conducted by eXelate in conjunction with Digiday found that advertisers and ad agencies tend to source their data from data providers and DSPs. Online marketers, by contrast, typically draw from CRM systems, third-party data providers, web-analytics tools, and marketing-automation platforms.
Data sources used by advertisers for look-alike modeling:
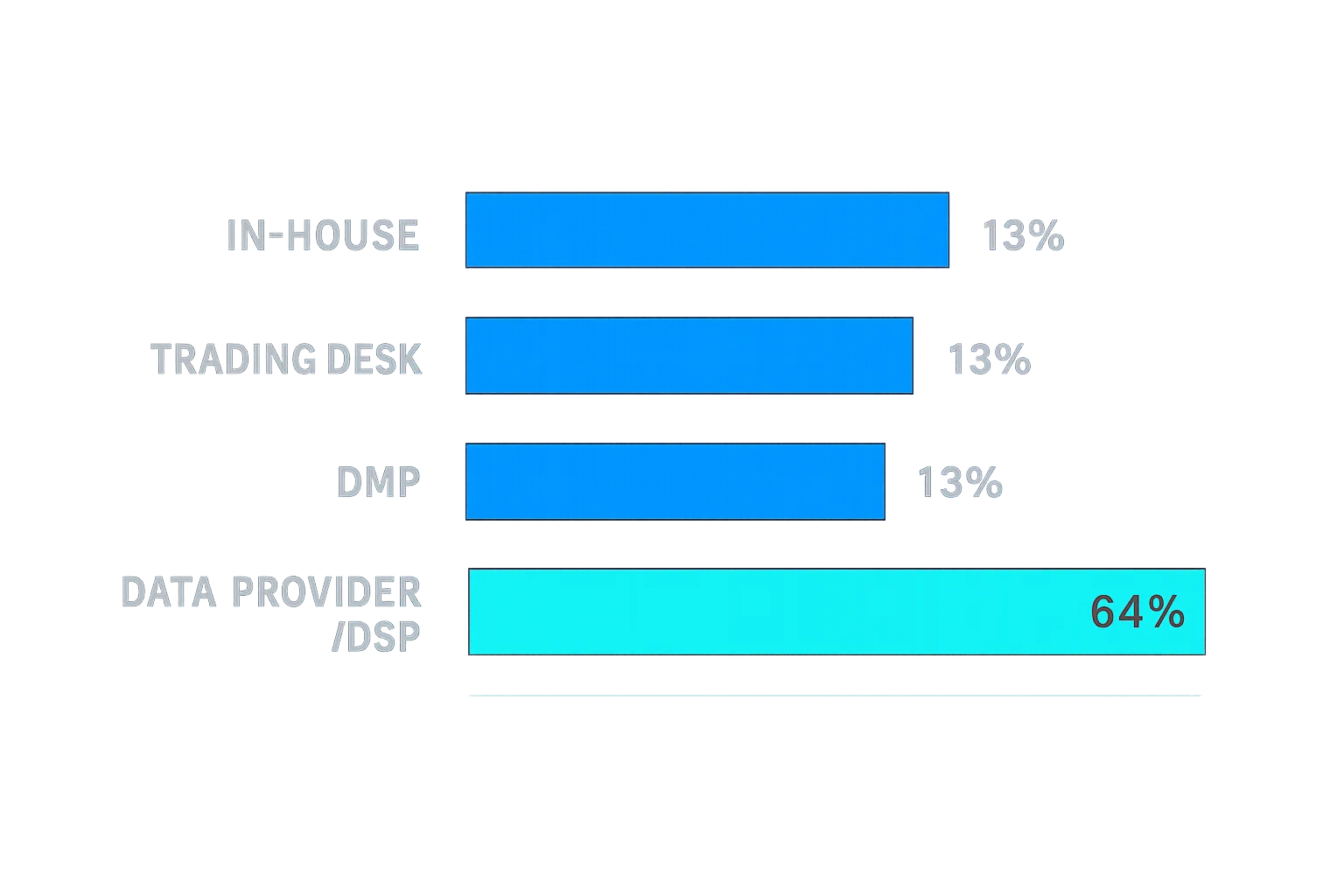
Data sources used by ad agencies for look-alike modeling:
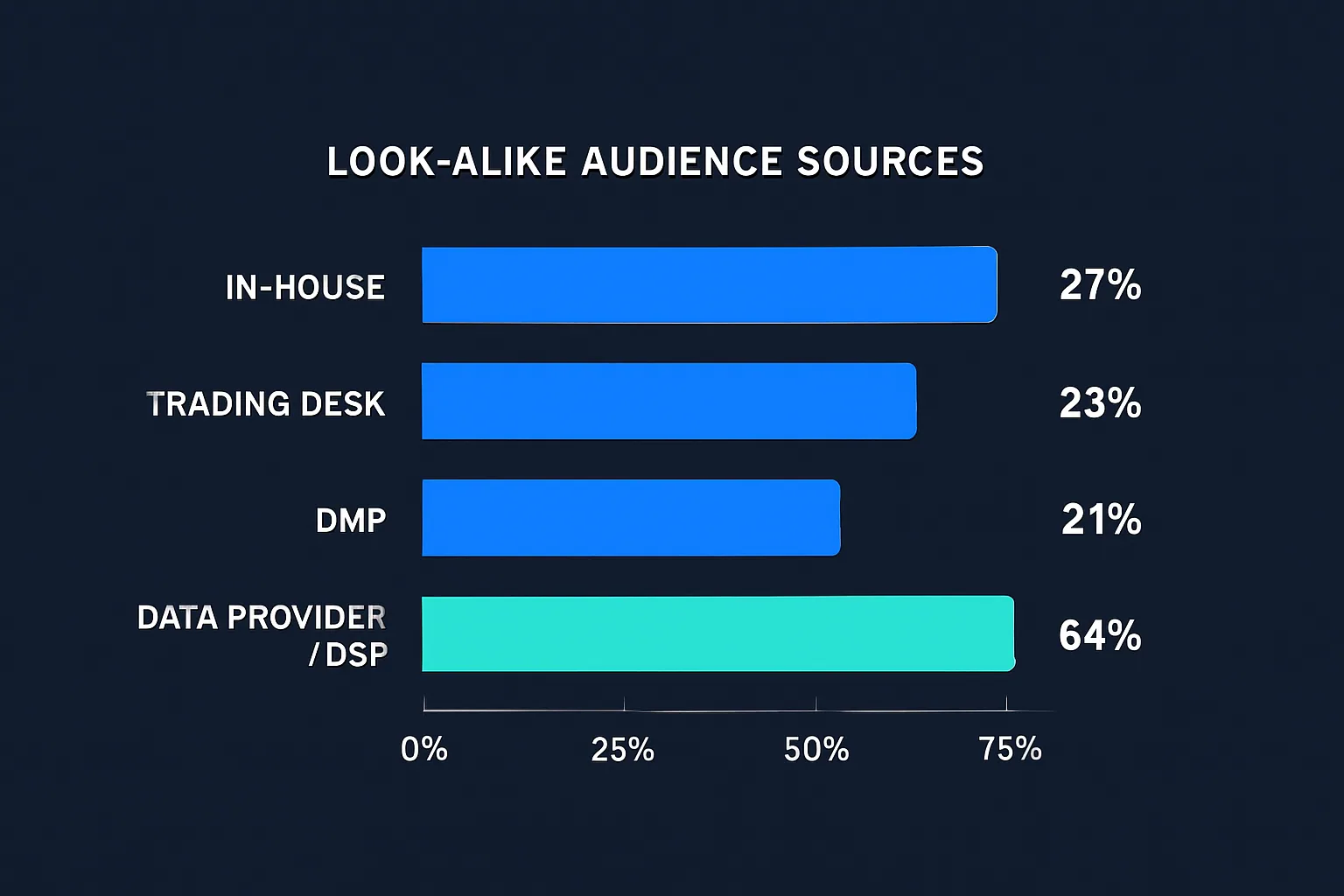
Step 2: Define the Attributes and Behaviours of Your Most Valuable Customers
Once the data is collected, the next step is to define exactly what makes a "best customer." This definition becomes the look-alike model itself — specifying the attributes, interests, and behaviours that characterize the audience worth replicating.
The strictness of the model directly affects the results:
- A tighter model (more attributes defined) produces a smaller audience but one that more closely mirrors the original high-value customers, improving the likelihood of strong campaign performance.
- A looser model (fewer attributes defined) casts a wider net, trading precision for reach — better suited to awareness objectives than conversion-focused ones.
The diagram below illustrates the difference between a tightly defined and a loosely defined look-alike model, using the e-commerce example:
look a like mixed tightly and loosely defined look-alike models
Step 3: Apply Algorithms to Extend the Audience
With the model defined, the DMP or DSP analyzes the seed audience — the pre-defined group of best customers — and applies proprietary algorithms to the collected data to surface user profiles that match it.
In effect, the platform takes one reference card (the seed audience) and scans the full data pool to find every profile that resembles it. The output is a new, extended audience of users who have never interacted with the business but who closely resemble those who have.
What Can Look-alike Modeling Be Used For?
Prospecting and Extending Campaign Reach
The primary use case for look-alike modeling is prospecting — finding net-new potential customers or site visitors who haven't yet been reached. Rather than targeting only people who are already known to the business, prospecting uses the look-alike model to identify similar users earlier in the funnel.
It also helps extend the reach of existing campaigns. If a campaign is targeting audiences based on a specific set of attributes (age, gender, location, interests), look-alike modeling can surface additional users who don't neatly fit those defined segments — either because there's insufficient data to classify them in the usual way, or because they carry different attributes altogether — yet who still closely resemble the business's best customers in meaningful ways.
Key Takeaways
Look-alike modeling is a practical, data-driven method for scaling audience acquisition without abandoning targeting quality. The quality of the seed audience definition and the breadth of data available are the two biggest factors determining how useful the resulting model will be. For most use cases, starting with a tighter model and loosening it as campaign data accumulates tends to produce better outcomes than opening reach too wide from the outset.